In industrial environments, robots are confronted with constantly changing working conditions and manipulation tasks. Traditional approaches that require robots to learn skills from scratch for new tasks are often slow and heavily dependent on human intervention. To address inefficiency and enhance robots' adaptability, we propose a general Intelligent Transfer System (ITS) that enables autonomous and rapid new skill learning in dynamic environments. ITS integrates Large Language Models (LLMs) with transfer reinforcement learning, harnessing both the advanced comprehension and generative capabilities of LLMs and the pre-acquired skill knowledge of robotic systems. First, to achieve comprehensive understanding of unseen task commands and enable autonomous skill learning in robots, we propose a reward function generation method based on task-specific reward components. This approach significantly improves time efficiency and accuracy while eliminating the need for manual design. Secondly, to accelerate the learning speed of new robotic skills, we propose an Intelligent Transfer Network (ITN) within the ITS. Unlike traditional methods that merely reuse or adapt existing skills, ITN intelligently integrates related skill features, significantly enhancing learning efficiency through synergistic knowledge fusion. We systematically evaluate our method in the simulation environment. The results demonstrate that the system can efficiently learn unseen skills without relying on pre-programmed behaviors, achieving significant improvements in time efficiency—specifically, 72.22% and 65.17% faster learning for two major tasks compared to learning from scratch. Supplementary materials are accessible via our project page:https://jkx-yy.github.io/
{
"instruction": "For the continuous operation task of the robot, according to the input task command, all the distance calculation components involved are listed step by step according to the execution order.",
"input": "The three small, medium and large gears on the table are pushed to the specified position in turn.",
"output": "1. Calculate the distance between the jaws and the small gear: distance_finger_to_small_gear\n2. Calculate the distance between the small gear and the small gear's target location: distance_small_gear_to_small_location\n3. Calculate the distance between the jaws and the medium gear: distance_finger_to_medium_gear\n5. Calculate the distance between the medium gear and the target location of the medium gear: distance_medium_gear_to_mediun_location\n5. Calculate the distance between the jaws and the large gear: distance_finger_to_large_gear\n6. Calculate the distance between the large gear and the target location of the large gear: distance_large_gear_to_large_location"
}
In this experiment, we list the generator's reward optimization process and compare the reward function generated by the generator with the reward function generated by Eureka and the manually designed reward function.
@torch.jit.script
def compute_reward(fingertip_midpoint_pos: Tensor, nut_pos: Tensor, bolt_tip_pos: Tensor) -> Tuple[Tensor, Dict[str, Tensor]]:
# Adjusted temperature parameters for reward transformations
temp_pick = torch.tensor(0.1) # Increased to make initial progress more rewarding
temp_place = torch.tensor(0.4) # Increase, make this step more rewarding
# Calculate Distance Based on reward_components
distance_finger_to_nut = torch.norm(fingertip_midpoint_pos - nut_pos, p=2, dim=-1)
distance_nut_to_bolttip = torch.norm(nut_pos - bolt_tip_pos, p=2, dim=-1)
# Adjusted rewards for each stage of the task with new scaling
reward_pick = -distance_finger_to_nut
reward_place = -distance_nut_to_bolttip
# Transform rewards with exponential function to normalize and control scale
reward_pick_exp = torch.exp(reward_pick / temp_pick)
reward_place_exp = torch.exp(reward_place / temp_place)
# Combine rewards for total reward, ensuring sequential completion by multiplication
total_reward = reward_pick_exp * reward_place_exp
# reward_components dictionary
rewards_dict = {
"reward_pick": reward_pick_exp,
"reward_place": reward_place_exp,}
return total_reward, rewards_dict
class FactoryTaskNutBoltPick(FactoryEnvNutBolt, FactoryABCTask):
"""Rest of the environment definition omitted."""
def compute_observations(self):
"""Compute observations."""
obs_tensors = [
self.fingertip_midpoint_pos,
self.fingertip_midpoint_quat,
self.fingertip_midpoint_linvel,
self.fingertip_midpoint_angvel,
self.bolt_tip_pos,
self.bolt_tip_quat,
self.nut_pos,
self.nut_quat,
]
self.obs_buf = torch.cat(obs_tensors, dim=-1)
pos=self.obs_buf.size()
com_vector=torch.full([pos[0],self.num_observations-pos[1]],0.0).to(self.device)
self.obs_buf = torch.cat((self.obs_buf,com_vector),-1)
return self.obs_buf
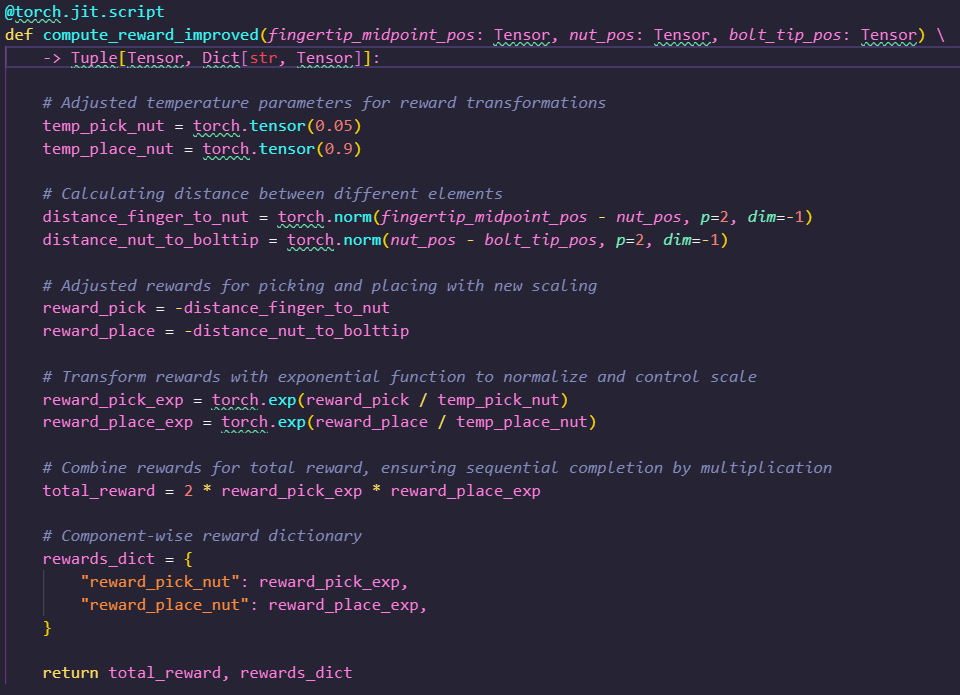
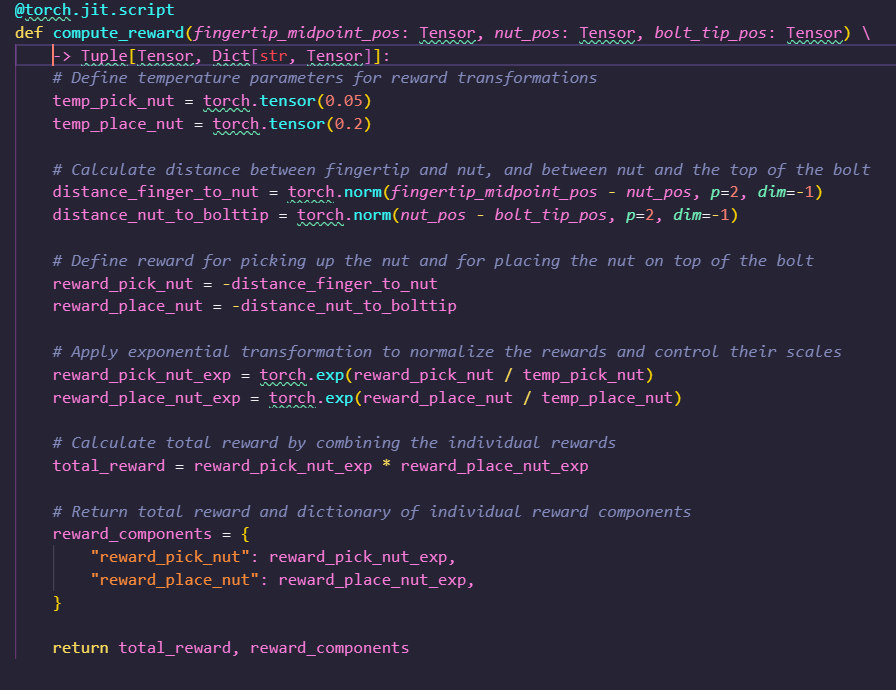
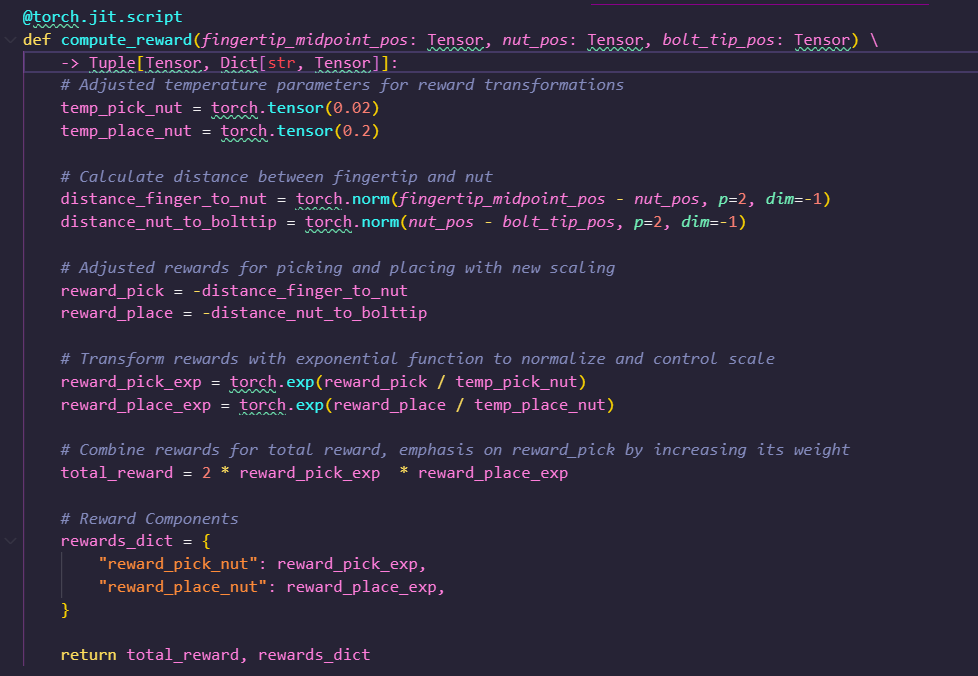
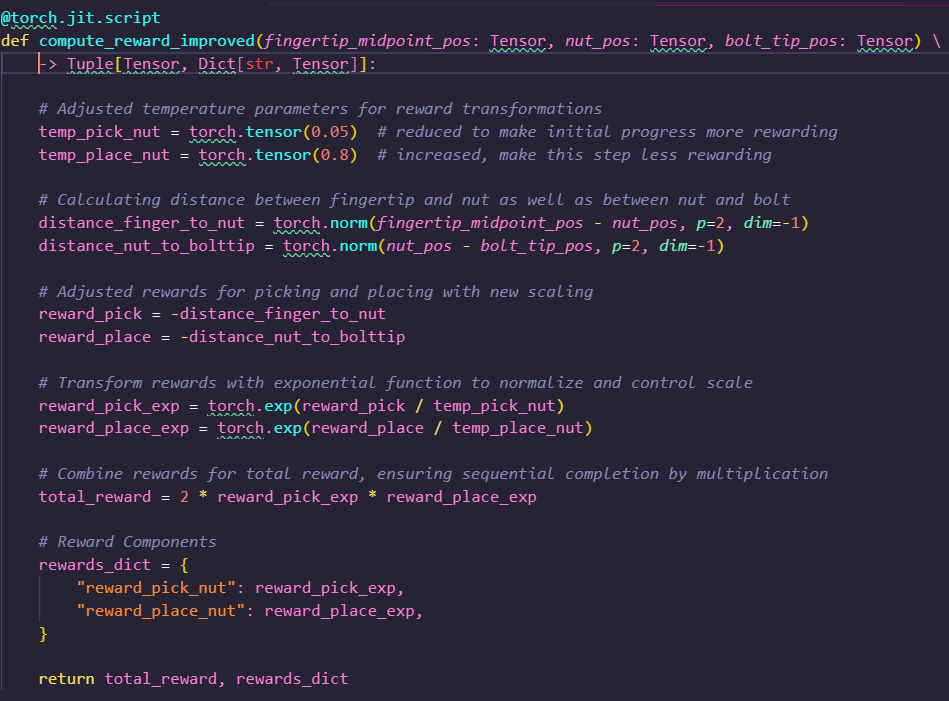
We trained a RL policy using the provided reward function code and tracked the values of the individual components in the reward function as well as global policy metrics such as success rates and episode lengths after every 11 epochs and the maximum, mean, minimum values encountered:
reward_pick: ['0.05', '0.06', '0.17', '0.40', '0.68', '0.72', '0.77', '0.79', '0.78', '0.79', '0.79'], Max: 0.80, Mean: 0.57, Min: 0.05
reward_lift: ['0.83', '0.83', '0.83', '0.83', '0.83', '0.83', '0.83', '0.84', '0.84', '0.86', '0.85'], Max: 0.86, Mean: 0.84, Min: 0.83
task_score: ['0.00', '0.00', '0.00', '0.02', '0.30', '0.53', '0.67', '0.77', '0.80', '0.87', '0.77'], Max: 0.91, Mean: 0.46, Min: 0.00
episode_lengths: ['119.00', '119.00', '119.00', '119.00', '119.00', '119.00', '119.00', '119.00', '119.00', '119.00', '119.00'], Max: 119.00, Mean: 119.00, Min: 119.00
Please carefully analyze the policy feedback and provide a new, improved reward function that can better solve the task. Some helpful tips for analyzing the policy feedback:
(1) If the success rate is always close to zero, it means that the sequential execution has failed to reach the last step, and you can infer that the task execution failed at the first step by analyzing the rewards for each subtask
(2) If the values for a certain reward_components are near identical throughout, then this means RL is not able to optimize this component as it is written. You may consider
(a) Changing its scale or the value of its temperature parameter
(b) Re-writing the reward_components
(c) Discarding the reward_components
(3) If some reward_components' magnitude is significantly larger, then you must re-scale its value to a proper range
Please analyze each existing reward_components in the suggested manner above first, and then write the reward function code. The output of the reward function should consist of two items:
(1) the total reward,
(2) a dictionary of each individual reward_components(reward dictionary for each sub-process)..
The code output should be formatted as a python code string: "```python ... ```".
Environmental observation code :
obs_tensors = [self.fingertip_midpoint_pos,
self.fingertip_midpoint_quat,
self.fingertip_midpoint_linvel,
self.fingertip_midpoint_angvel,
self.gear_small_pos,
self.gear_small_quat,
self.gear_medium_pos,
self.gear_medium_quat,
self.gear_large_pos,
self.gear_large_quat,
self.small_location_pos,
self.small_location_quat,
self.medium_location_pos,
self.medium_location_quat,
self.large_location_pos,
self.large_location_quat]
Generated reward_components :
1. Calculate the distance between the jaws and the small gear: distance_finger_to_small_gear
2. Calculate the distance between the small gear and the small gear’s target location: distance_small_gear_to_small_location
3. Calculate the distance between the jaws and the medium gear: distance_finger_to_medium_gear
4. Calculate the distance between the medium gear and the target location of the medium gear: distance_medium_gear_to_medium_location
5. Calculate the distance between the jaws and the large gear: distance_finger_to_large_gear
6. Calculate the distance between the large gear and the target location of the large gear: distance_large_gear_to_large_location
...
temp_pick = torch.tensor(0.1)
temp_carry = torch.tensor(0.2)
temp_place = torch.tensor(0.3)
# Calculate distances
distance_finger_to_small_gear = torch.norm(gear_small_pos - fingertip_midpoint_pos, p=2, dim=-1)
distance_small_gear_to_small_location = torch.norm(gear_small_pos - self.small_location_pos, p=2, dim=-1)
distance_finger_to_medium_gear = torch.norm(gear_medium_pos - fingertip_midpoint_pos, p=2, dim=-1)
distance_medium_gear_to_mediun_location = torch.norm(gear_medium_pos - self.medium_location_pos, p=2, dim=-1)
distance_finger_to_large_gear = torch.norm(gear_large_pos - fingertip_midpoint_pos, p=2, dim=-1)
distance_large_gear_to_large_location = torch.norm(gear_large_pos - self.large_location_pos, p=2, dim=-1)
# Define rewards for small gear
reward_pick_small = -distance_finger_to_small_gear
reward_carry_small = distance_small_gear_to_small_location
reward_place_small = -torch.abs(distance_small_gear_to_small_location - torch.tensor(0.0))
# Transform small gear rewards
reward_pick_small_exp = torch.exp(reward_pick_small /temp_pick)
reward_carry_small_exp = torch.exp(reward_carry_small /temp_carry)
reward_place_small_exp = torch.exp(reward_place_small /temp_place)
# Define rewards for medium gear
reward_pick_medium = -distance_finger_to_medium_gear
reward_carry_medium = distance_medium_gear_to_mediun_location
reward_place_medium = -torch.abs(distance_medium_gear_to_mediun_location - torch.tensor(0.0)) # Ideally, this distance is zero
# Transform medium gear rewards
reward_pick_medium_exp = torch.exp(reward_pick_medium /temp_pick)
reward_carry_medium_exp = torch.exp(reward_carry_medium /temp_carry)
reward_place_medium_exp = torch.exp(reward_place_medium /temp_place)
# Define rewards for large gear
reward_pick_large = -distance_finger_to_large_gear
reward_carry_large = distance_large_gear_to_large_location
reward_place_large = -torch.abs(distance_large_gear_to_large_location - torch.tensor(0.0)) # Ideally, this distance is zero
# Transform large gear rewards
reward_pick_large_exp = torch.exp(reward_pick_large/temp_pick )
reward_carry_large_exp = torch.exp(reward_carry_large /temp_carry)
reward_place_large_exp = torch.exp(reward_place_large /temp_place)
...
self.rew_buf[:], self.rew_dict = compute_reward(self.fingertip_midpoint_pos, self.gear_small_pos, self.gear_small_target_pos, self.gear_medium_pos, self.gear_medium_target_pos, self.gear_large_pos, self.gear_large_target_pos)
AttributeError: 'FactoryTaskGearsPickPlaceGPT' object has no attribute 'gear_small_target_pos'
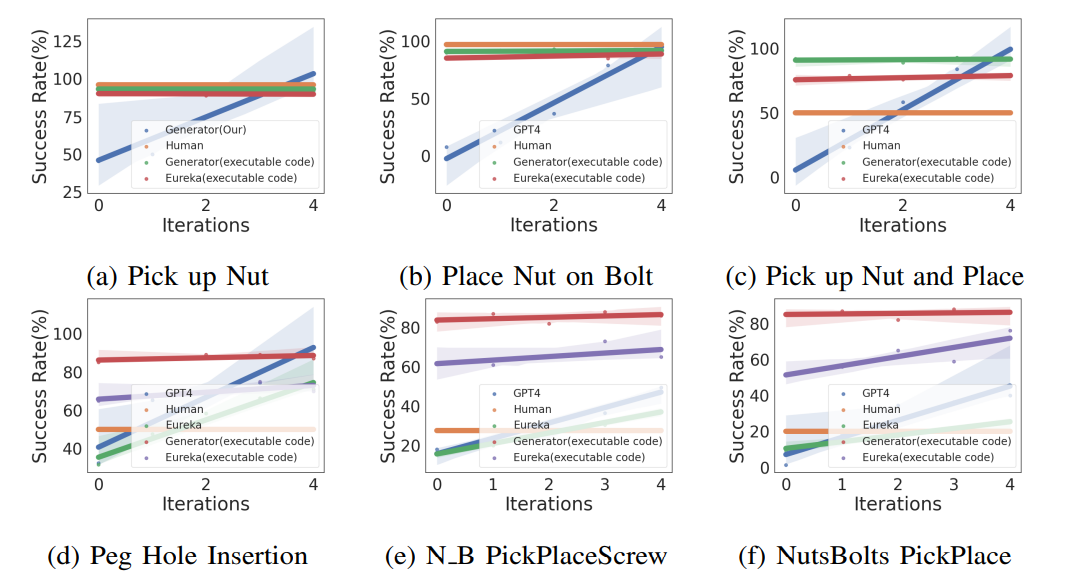
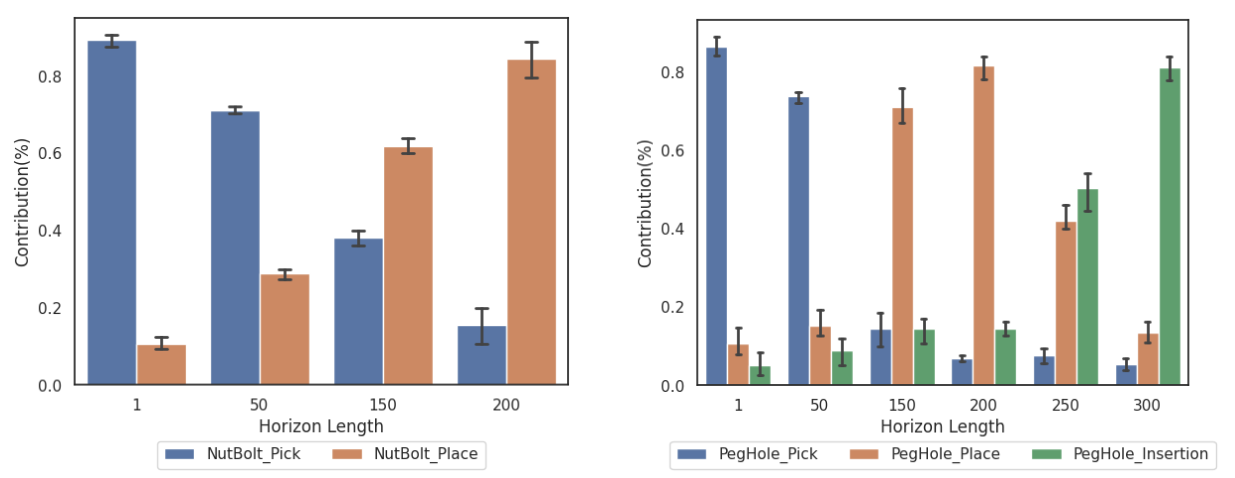
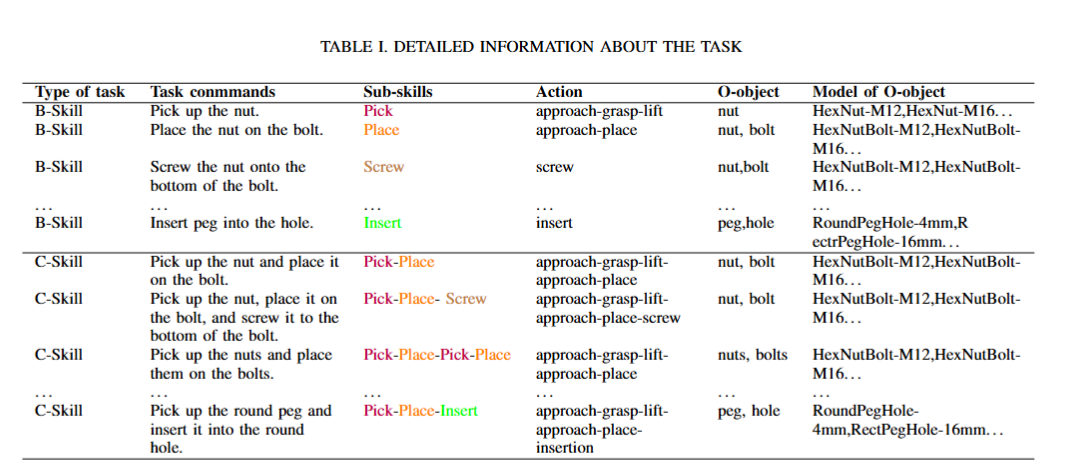
We utilize the four basic skills and complex skills of the industrial assembly of robots to compose the entire experiment. Among them, the sequential complex skills are combinations of various basic skills.
In the video below, we demonstrate each of the four basic skills to operate different models of mechanical parts using the reward function generated by the generator.
In the following video, we show two complex skills composed of basic skills: the NutBolt task and the PegHole task. The robot operates parts of different types and sizes. In each task, ITS uses the reward function generated by the generator and uses the skills of the source domain to transfer learning to the target task. The entire process, from receiving a new task command to the robot autonomously and quickly completing this task, was performed without human involvement.
In the following videos, we give the results of applying the No_transfer vs ITN(ours) in two tasks, NutBolt_PickPlace and PegHole_Insert.Applying ITN's system to learn new skills is much more efficient.